ETH Zurich
Switzerland, 2026
Over the past years, mobile AI-based applications are becoming more and more ubiquitous. Various deep learning models can now be found on any mobile device starting from smartphones running LLMs, image enhancement, portrait segmentation, face recognition and neural generation models, to IoT platforms performing real-time image classification or smart-TV boards coming with sophisticated image super-resolution algorithms. The performance of mobile NPUs and DSPs is also increasing dramatically, making it possible to run complex deep learning models and to achieve fast runtime in the majority of tasks.
While many research works targeted at efficient deep learning models have been proposed recently, the evaluation of the obtained solutions is usually happening on desktop CPUs and GPUs, making it nearly impossible to estimate the actual inference time and memory consumption on real mobile hardware. To address this problem, we introduce the first Mobile AI Workshop, where all deep learning solutions are developed for and evaluated on mobile devices.
Due to the performance of the last-generation mobile AI hardware, the topics considered in this workshop will go beyond the simple classification tasks, and will include such challenging problems as image denoising, efficient LLM and Stable Diffusion, learned image ISP pipeline, smartphone photo enhancement, real-time image and video super-resolution. All information about the challenges, papers, invited talks and workshop industry partners is provided below.
LIVE
Join the main workshop Zoom conference for a Q&A session: https://ethz.zoom.us/j/69792970453
SCHEDULE


Deploying Deep Learning Models on Mobile NPUs: What's New in 2026?
09:00 Denver Time ┈ Andrey Ignatov ┈ AI Benchmark Project Lead, ETH Zurich
Abstract: In this tutorial, we will review the recent Android AI software stack updates, and will talk about the performance of the latest mobile chipsets from Qualcomm, MediaTek, Google, Samsung and Unisoc released during the past year. We will also discuss the power efficiency of mobile chipsets and their NPUs, and will analyze their energy consumption for a number of typical AI workloads.

Turning Computer Vision into Premium Experiences at the Edge
09:30 Denver Time ┈ Felix Baum ┈ Director Product Management, Qualcomm Technologies
Abstract: Most of the traditional and agentic AI-based mobile use cases revolve around camera and computer vision technologies. In this session, I'll kick things off by highlighting some of these applications, then expand the discussion to include ambient-based technologies and their use cases. We'll take a brief look at trends in adjacent markets, such as XR glasses and explore how computer vision and machine learning are elevating user experiences. Finally, I'll wrap up by describing the options developers have for designing, debugging and deploying workloads on hardware—ranging from community-driven frameworks to custom offerings.
10:10 Denver Time Efficient INT8 Single-Image Super-Resolution via Deployment-Aware Quantization
☉ University of Information Technology & Ho Chi Minh City University of Technology & Vietnam National University
10:45 Denver Time FastSHADE: Fast Self-augmented Hierarchical Asymmetric Denoising for Efficient Inference
☉ Fanis, London, UK
11:00 Denver Time Real Image Denoising with Knowledge Distillation for High-Performance Mobile NPUs
☉ University of Wuerzburg, Germany
11:25 Denver Time Bridging the Training-Deployment Gap: Gated Encoding and Multi-Scale Refinement for Efficient Quantization-Aware Image Enhancement
☉ Vietnam National University & Da Nang University of Economics
12:00 Denver Time LiteBokeh: Compact Model for Real-time Bokeh Rendering
☉ ZTE Corporation
12:15 Denver Time Break & Lunch
13:00 Denver Time Accelerating On-Device LLM Inference via Activation-guided FFN Distillation on Raspberry Pi
☉ Korea Electronics Technology Institute
13:15 Denver Time RealisMobile: High-Fidelity Image Generation and Inference Acceleration System for Mobile Devices using Realistic Vision
☉ OmniVision-IDT Joint Laboratory for Intelligent Image Sensing & Eastern Institute of Technology, Ningbo & The Hong Kong Polytechnic University
13:30 Denver Time EdgeDiT: Hardware-Aware Diffusion Transformers for Efficient On-Device Image Generation
☉ Samsung Research Institute Bangalore, India
13:45 Denver Time Quantization with Unified Adaptive Distillation to enable multi-LoRA Based One-For-All Generative Vision Models on Edge
☉ Samsung Research Institute Bangalore, India
14:00 Denver Time Slimmable ConvNeXt: Width-Adaptive Inference for Efficient Multi-Device Deployment
☉ Kiel University & Hamburg University of Technology & UNU-INWEH
14:15 Denver Time MobileAgeNet: Lightweight Facial Age Estimation for Mobile Deployment
☉ University of Wuerzburg, Germany
14:30 Denver Time ZCLIP: Generalization-Aware Compression and Geometry-Preserving Continual Learning for Vision-Language Models on Edge Devices
☉ Oakland University
14:45 Denver Time RGB is (Almost) All You Need: Estimating Soil Parameters Using TerraMind
☉ Silesian University of Technology & Opole University of Technology & Φ-Lab, ESA
15:00 Denver Time Discussion & Wrap Up
CHALLENGES
4K Image Super-Resolution

 | Evaluation Platform: Snapdragon 8 Elite G5 NPU |
4K Image Super-Resolution
| Evaluation Platform: Dimensity 9500 NPU |
Video Super-Resolution

| Evaluation Platform: Arm Mali / Adreno GPU |
Efficient LLMs

| Evaluation Platform: Raspberry Pi 8GB |
Efficient Stable Diffusion

| Evaluation Platform: Apple M4 Neural Engine |
Image Denoising

| Evaluation Platform: Arm Mali / Adreno GPU |
Bokeh Effect Rendering

| Evaluation Platform: Arm Mali / Adreno GPU |
RGB Photo Enhancement

| Evaluation Platform: Arm Mali / Adreno GPU |
Learned Smartphone ISP

| Evaluation Platform: Arm Mali / Adreno GPU |
MAI 2025 CHALLENGE REPORTS
Image Super-Resolution
| Evaluation Platform: Google Tensor TPU |
RGB Photo Enhancement
| Evaluation Platform: Arm Mali / Adreno GPU |
Learned Smartphone ISP
| Evaluation Platform: Arm Mali / Adreno GPU |
PREVIOUS CHALLENGES (2022)
Video Super-Resolution
| Evaluation Platform: MediaTek Dimensity APU |
| Powered by: |  |
Image Super-Resolution
| Evaluation Platform: Synaptics Dolphin NPU |
| Powered by: |  |
Learned Smartphone ISP
| Evaluation Platform: Snapdragon Adreno GPU |
| Powered by: |  |
Bokeh Effect Rendering
| Evaluation Platform: Arm Mali GPU |
| Powered by: |  |
Depth Estimation

| Evaluation Platform: Raspberry Pi 4 |
| Powered by: |  |
PREVIOUS CHALLENGES (2021)
Learned Smartphone ISP
| Evaluation Platform: MediaTek Dimensity APU |
| Powered by: | |
Image Denoising
| Evaluation Platform: Exynos Mali GPU |
| Powered by: |  |
Image Super-Resolution
| Evaluation Platform: Synaptics Dolphin NPU |
| Powered by: | |
Video Super-Resolution
| Evaluation Platform: Snapdragon Adreno GPU |
| Powered by: | |
Depth Estimation
| Evaluation Platform: Raspberry Pi 4 |
| Powered by: | |
Camera Scene Detection

| Evaluation Platform: Apple Bionic |
| Powered by: |  |
CALL FOR PAPERS
Being a part of CVPR 2026, we invite the authors to submit high-quality original papers proposing various machine learning based solutions for mobile, embedded and IoT platforms. The topics of interest cover all major aspects of AI and deep learning research for mobile devices including, but not limited to:
• Efficient deep learning models for mobile devices |
• Image / video super-resolution on low-power hardware |
• Efficient LLM architectures for mobile devices |
• Optimized Stable Diffusion for mobile devices |
• General smartphone photo and video enhancement |
• Deep learning applications for mobile camera ISPs |
• Fast image classification / object detection algorithms |
• Real-time semantic image segmentation |
• Image or sensor based identity recognition |
• Activity recognition using smartphone sensors |
• Depth estimation w/o multiple cameras |
• Portrait segmentation / bokeh effect rendering |
• Perceptual image manipulation on mobile devices |
• NLP models optimized for mobile inference |
• Artifacts removal from mobile photos / videos |
• RAW image and video processing |
• Low-power machine learning inference |
• Machine and deep learning frameworks for mobile devices |
• AI performance evaluation of mobile and IoT hardware |
• Industry-driven applications related to the above problems |
To ensure high quality of the accepted papers, all submissions will be evaluated by research and industry experts from the corresponding fields. All accepted workshop papers will be published in the CVPR 2026 Workshop Proceedings by Computer Vision Foundation Open Access and IEEE Xplore Digital Library. The authors of the best selected papers will be invited to present their work during the actual workshop event at CVPR 2026. The detailed submission instructions and guidelines can be found here.
SUBMISSION DETAILS @ CVPR
| Format and paper length | A paper submission has to be in English, in pdf format, and at most 8 pages (excluding references) in double column. The paper format must follow the same guidelines as for all CVPR 2026 submissions: https://cvpr.thecvf.com/Conferences/2026/AuthorGuidelines |
| Author kit | The author kit provides a LaTeX2e template for paper submissions. Please refer to this kit for detailed formatting instructions: https://github.com/cvpr-org/author-kit/archive/refs/tags/CVPR2026-v1(latex).zip |
| Double-blind review policy | The review process is double blind. Authors do not know the names of the chair / reviewers of their papers. Reviewers do not know the names of the authors. |
| Dual submission policy | Dual submission is allowed with CVPR 2026 main conference only. If a paper is submitted also to CVPR and accepted, the paper cannot be published both at the CVPR and the workshop. |
| Proceedings | Accepted and presented papers will be published after the conference in CVPR Workshops proceedings together with the CVPR 2026 main conference papers. |
| Submission site * | https://cmt3.research.microsoft.com/MAIWC2026/ |
| * The Microsoft CMT service was used for managing the peer-reviewing process for this conference. This service was provided for free by Microsoft and they bore all expenses, including costs for Azure cloud services as well as for software development and support. |
TIMELINE
| Workshop Event | Date [ Pacific Time, 2026 ] |
|---|---|
| Website online | January 20 |
| Paper submission server online | February 9 |
| Paper submission deadline [early submission] | March 10 |
| Paper decision notification [early submission] | March 25 |
| Paper submission deadline [late submission & challenge papers] | March 22 |
| Paper decision notification [late submission] | March 25 |
| Camera ready deadline | April 8 |
| Workshop day | June 4 |
| Challenges | Date [ Pacific Time, 2026 ] |
|---|---|
| Website online | January 15 |
| Validation server online | February 1 |
| Test phase begins, test data released | March 10 |
| Test phase submission deadline | March 19 |
| Fact sheets, code/executable submission deadline | March 19 |
| Preliminary test results release to the participants | March 21 |
| Paper submission deadline for entries from the challenges | March 22 |
DEEP LEARNING ON MOBILE DEVICES: TUTORIAL
Have some questions? Leave them on the AI Benchmark Forum
RUNTIME VALIDATION
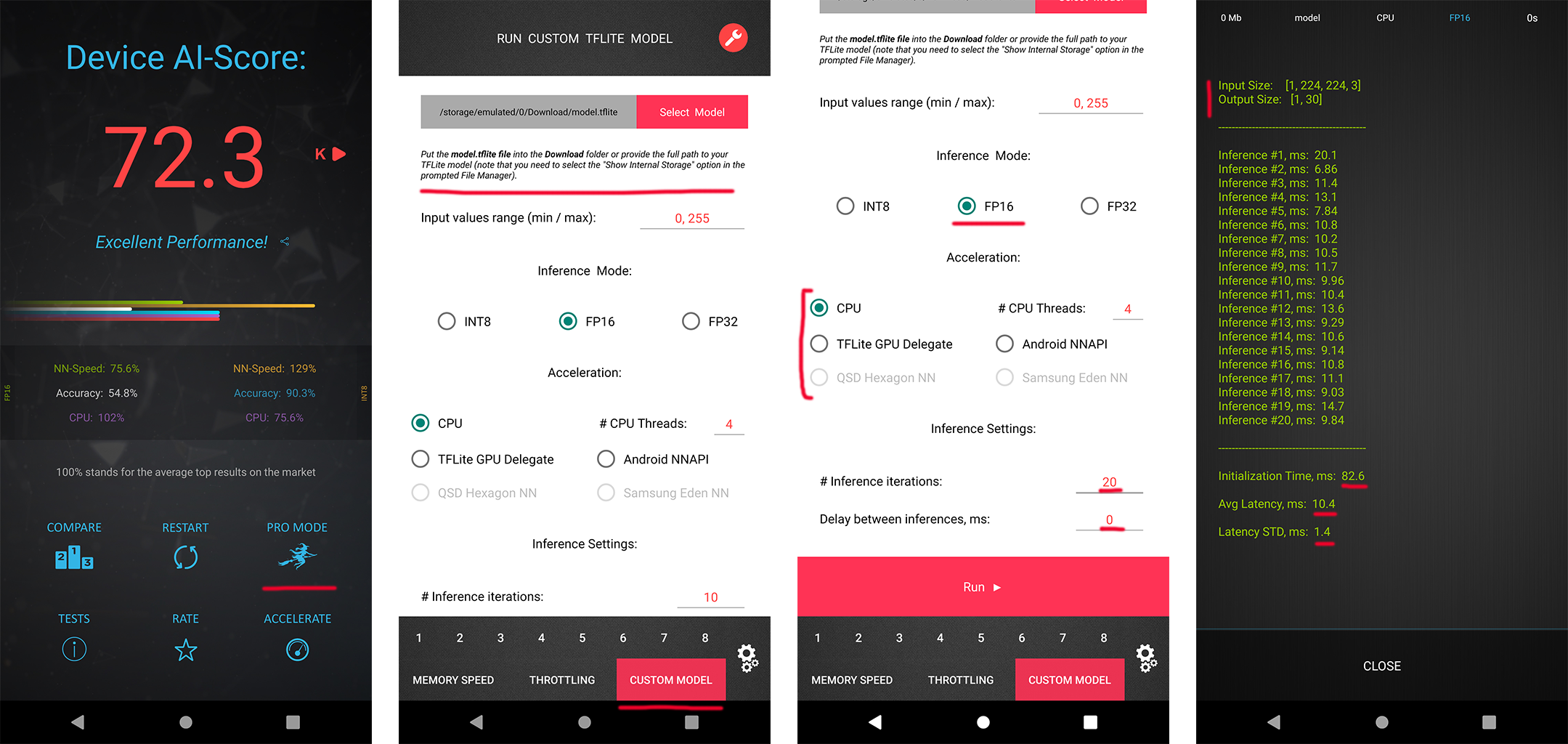
In each MAI 2026 challenge track, the participants have a possibility to check the runtime of their solutions remotely on the target platforms. For this, the converted TensorFlow Lite models should be uploaded to a special web-server, and their runtime on the actual target devices will be returned instantaneously or withing 24 hours, depending on the track. The detailed model conversion instructions and links can be found in the corresponding challenges. Besides that, we strongly encourage the participants to check the speed and RAM consumption of the obtained models locally on your own Android devices. This will allow you to perform model profiling and debugging faster and much more efficiently. To do this, one can use AI Benchmark application allowing you to load a custom TFLite model and run it with various acceleration options, including CPU, GPU, DSP and NPU: 1. Download AI Benchmark from the Google Play / website and run its standard tests. 2. After the end of the tests, enter the PRO Mode and select the Custom Model tab there. 3. Rename the exported TFLite model to model.tflite and put it into the Download folder of your device. 4. Select your mode type, the desired acceleration / inference options and run the model. You can find the screenshots demonstrating these 4 steps below:
CONTACTS
 |
Computer Vision Lab ETH Zurich, Switzerland andrey@vision.ee.ethz.ch |
 |
Computer Vision Laboratory University of Würzburg, Germany radu.timofte@uni-wuerzburg.de |
ETH Zurich
Switzerland, 2026