
Computer Vision Laboratory, ETH Zurich
Switzerland, 2021
Over the past years, mobile AI-based applications are becoming more and more ubiquitous. Various deep learning models can now be found on any mobile device, starting from smartphones running portrait segmentation, image enhancement, face recognition and natural language processing models, to smart-TV boards coming with sophisticated image super-resolution algorithms. The performance of mobile NPUs and DSPs is also increasing dramatically, making it possible to run complex deep learning models and to achieve fast runtime in the majority of tasks.
While many research works targeted at efficient deep learning models have been proposed recently, the evaluation of the obtained solutions is usually happening on desktop CPUs and GPUs, making it nearly impossible to estimate the actual inference time and memory consumption on real mobile hardware. To address this problem, we introduce the first Mobile AI Workshop, where all deep learning solutions are developed for and evaluated on mobile devices.
Due to the performance of the last-generation mobile AI hardware, the topics considered in this workshop will go beyond the simple classification tasks, and will include such challenging problems as image denoising, HDR photography, accurate depth estimation, learned image ISP pipeline, real-time image and video super-resolution. All information about the challenges, papers, invited talks and workshop industry partners is provided below.
ORGANIZERS

LIVE
Have some questions to the speakers? Leave them on the AI Benchmark Forum ⇢
SCHEDULE


Deep Learning on Smartphones, an In-Depth-Dive: Frameworks and SDKs, Hardware Acceleration with NPUs and GPUs, Models Deployment, Performance and Power Consumption Analysis
07:00 Pacific Time ┈ Andrey Ignatov ┈ AI Benchmark Project Lead, ETH Zurich
Abstract: In this tutorial, we will cover all basic concepts, steps and optimizations required for efficient AI inference on mobile devices. First, you will get to know how to run any NN model on your own smartphone in less than 5 minutes. Next, we will review all components needed to convert and run TensorFlow or PyTorch neural networks on Android and iOS smartphones, as well as discuss the key optimizations required for fast ML inference on the edge devices. In the second part of the talk, you will get an overview of the performance of all mobile processors with AI accelerators released in the past five years. We will additionally discuss the power consumption of the latest high-end smartphone SoCs, answering the question of why NPUs and DSPs are so critical for on-device inference.


Edge AI Technology – from Development to Deployment
08:20 Pacific Time ┈ Dr. Allen Lu ┈ Senior Director, Computing and AI Technology Group at MediaTek
Abstract: This presentation will share Mediatek’s experience in 5G+edge AI technology development and deployment. We use smart phone as an example to illustrate the edge AI technology evolution, from feature extraction for face unlock, to image / instance segmentation for video bokeh, to pixel-level AI algorithm for image and video noise reduction and super resolution. The picture and video quality are significantly better than the conventional method in the low light and high dynamic range photo scenarios. While the state of the art 5G+AI SoC packs tens of billions of transistors on a single centimeter by centimeter silicon chip for this achievement, the SoC complexity increases over time with a higher slope than the Moore’s law can offer. We will discuss the technology improvement to bridge this gap. It’s the combination of process improvement, HW architecture improvement, and SW/algorithm complexity reduction to enable new edge AI applications and enrich our digital life experience.
09:05 Pacific Time CSANet: High Speed Channel Spatial Attention Network for Mobile ISP
☉ Industrial Technology Research Institute & National Yang Ming Chiao Tung University, Taiwan

Imagination Technologies Approach to Overcame the Challenges of Deploying AI in Mobile
09:10 Pacific Time ┈ Gilberto Rodriguez ┈ Director of AI Product Management at Imagination Technologies
Abstract: Mobile devices are nowadays very powerful heterogeneous engines, but they still have limitations of what you can achieve of them. With a growing number of applications using AI as part of their solution and the concerns about privacy of data, having efficient hardware and tools for deploying AI is the only path to success in the field. In this workshop, I will explain some of the techniques that can be used to optimise Neural Networks for a better deployment and how Imagination Technologies develops efficient hardware architectures for mobile devices.


Samsung Exynos Mobile NPUs and SDK: Hardware Design, Performance, Models Deployment and Efficient Inference
09:50 Pacific Time ┈ Jihoon Bang ┈ NPU and DSP Software Development Management at Samsung SLSI
Abstract: Samsung Exynos NPUs are now being widely used in numerous mobile, IoT and autonomous driving systems. This talk will provide an overview of their hardware design as well as the full software NN stack used for efficient models deployment. It will show how to perform models profiling and optimization with the Exynos Tools allowing to achieve the best performance on Exynos-based devices. Finally, several real-world applications that are using Samsung NPUs will be presented, and the future mobile NN development directions and challenges will be discussed.
10:20 Pacific Time Low Bandwidth Video-Chat Compression using Deep Generative Models
☉ Facebook & INRIA, France
10:30 Pacific Time AsymmNet: Towards Ultralight Convolution Neural Networks Using Asymmetrical Bottlenecks
☉ Alibaba Cloud & Hasso Plattner Institute & ByteDance
10:35 Pacific Time Pseudo-IoU: Improving Label Assignment in Anchor-Free Object Detection
☉ UIUC & MIT-IBM Watson AI Lab & IBM T.J. Watson Research Center & NVIDIA & University of Oregon & Picsart AI Research (PAIR)



Android Neural Networks API - What's New and Best Practices
10:40 Pacific Time ┈ Przemysław Szczepaniak ┈ Software Engineer at Google
10:55 Pacific Time ┈ Mika Raento ┈ Software Engineer at Google
Abstract: The Android Neural Networks API (NNAPI) was introduced in Android O-MR1, late 2017. NNAPI provides a standard hardware abstraction layer for ML accelerators on Android as part of the operating system, allowing accelerated computation over a graph of neural network layers. NNAPI has been successful in allowing access to previously hard-to-access hardware. However, its slow speed of evolution and lack of performance and correctness guarantees have made adoption by applications limited. In this talk we share recent advances for both of those problems. We'll describe how we are making NNAPI updatable outside Android OS releases through Google Play Services. We'll also talk about how to automatically deal with performance and correctness through a mini-benchmark embedded in TFLite models.
11:20 Pacific Time Extremely Lightweight Quantization Robust Single-Image Super Resolution for Mobile Devices
☉ Aselsan Research, Turkey
11:25 Pacific Time Anchor-based Plain Net for Mobile Image Super-Resolution
☉ Nanjing Ubiversity, China

AI on the Edge @Synaptics : HW and SW Products and Development
11:30 Pacific Time ┈ Abdel Younes ┈ Technical Director, Smart Home Solutions Architecture at Synaptics
Abstract: New AI-at-the-edge processors with improved efficiencies and flexibility are unleashing a huge opportunity to democratize computer vision broadly across all markets, enabling edge AI devices with small, low-cost, low-power cameras. Synaptics has embarked on a roadmap of edge-AI DNN processors targeted at a range of real-time computer vision and multimedia applications. In this talk, we will describe the hardware architecture used in Synaptics VideoSmart™ VS600 family with embedded built-in Neural Processor Unit and we will show how the SyNAP™ Software framework enables lightweight and optimized AI applications such as real-time Video SuperResolution upscaling.
12:00 Pacific Time Break & Lunch


AI Deployment from Hardware to Software – Challenges and Opportunities
12:30 Pacific Time ┈ Emilia Tantar ┈ Chief Data and Artificial Intelligence, Black Swan LUX
Abstract: AI has become a basic capability of consumer electronics and is continuously changing the user experience. Higher peak computing power and higher energy efficiency depend on the collaborative optimization of software and hardware. HUAWEI through the HiAI Foundation continuously provides leading solutions in key technologies such as NPU hardware architecture, heterogeneous computing framework, and quantitative search tools. Through a complete approach spanning from hardware to AI software modules will showcase a better intelligent experience for consumers on multiple devices.
13:10 Pacific Time EVSRNet:Efficient Video Super-Resolution with Neural Architecture Search
☉ ZTE Corporation, China


Learning to See the World Clearer
13:15 Pacific Time ┈ Jie Cai ┈ Research Scientist at OPPO
Abstract: Recent progress in video super-resolution has been remarkable. However, since most of the recent approaches are deep learning based, they are way too computationally intensive to be deployed on edge devices. Besides, it is still a challenge to recover real-world videos with a variety of degradations. In this talk, an approach for real-time video super-resolution on mobile devices is presented, wihch is able to deal with a wide range of degradations. In addiation, it achieves state-of-the-art performance on a public video super-resolution dataset and has been delivered to OPPO smartphones.
13:50 Pacific Time A Simple Baseline for Fast and Accurate Depth Estimation on Mobile Devices
☉ Tencent GY-Lab, China
14:00 Pacific Time Knowledge Distillation for Fast and Accurate Monocular Depth Estimation on Mobile Devices
☉ Huazhong University of Science and Technology, China
14:05 Pacific Time Real-time Monocular Depth Estimation with Sparse Supervision on Mobile
☉ Samsung Research, UK & Information Technologies Institute, Greece
14:10 Pacific Time Fast and Accurate Camera Scene Detection on Smartphones
☉ ETH Zurich, Switzerland
14:25 Pacific Time MobileHumanPose: Toward real-time 3D human pose estimation in mobile devices
☉ Korea Advanced Institute of Science and Technology, Republic of Korea

Hate it or Love it, Your SW Stack Defines Application Performance and Reach: An Overview or our HW and SW
14:30 Pacific Time ┈ Felix Baum ┈ Director Product Management, Qualcomm Technologies
Abstract: Qualcomm has worked extensively on its state-of-the-art Qualcomm Neural Network and software stack including the Qualcomm Neural Processing SDK and the AI Model Efficiency Toolkit. By doing so Qualcomm has helped many developers take their applications to the next level with extreme efficiency and performance. In this talk, we will take you through some of the most common misconceptions related to software stacks and AI frameworks, and how these have a direct and indirect impact to application performance and reach. If you are interested in improving your application performance or even porting over to ML this talk is for you.
15:00 Pacific Time Do All MobileNets Quantize Poorly? Gaining Insights into the Effect of Quantization on Depthwise Separable Convolutional Networks Through the Eyes of Multi-scale Distributional Dynamics
☉ University of Waterloo & Waterloo Artificial Intelligence Institute, Canada
15:05 Pacific Time Layer Importance Estimation with Imprinting for Neural Network Quantization
☉ University of Alberta & Huawei, Canada
15:10 Pacific Time Computer Vision-based Assistance System for the Visually Impaired Using Mobile Edge AI
☉ Kutir Technologies Corporation, Canada & Denbar Robotics, USA & Molecular Forecaster Inc., Canada & University of Georgia, USA
15:15 Pacific Time RSCA: Real-time Segmentation-based Context-Aware Scene Text Detection
☉ InnoPeak Technology & UIUC & University of Oregon, USA
15:20 Pacific Time Real-time analogue gauge transcription on mobile phone
☉ University of Cambridge, UK
15:25 Pacific Time Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering
☉ IIT Madras & Jadavpur University & IIT Jodhpur, India
15:30 Pacific Time Filtering Empty Camera Trap Images in Embedded Systems
☉ Federal University of Amazonas, Brazil
15:35 Pacific Time DeepShift: Towards Multiplication-Less Neural Networks
☉ Huawei Technologies & Universitiy of Toronto, Canada
15:40 Pacific Time Wrap Up & Closing
CHALLENGES
Learned Smartphone ISP

 | Evaluation Platform: MediaTek Dimensity APU |
| Powered by: | |
Image Denoising

| Evaluation Platform: Exynos Mali GPU |
| Powered by: | |
Image Super-Resolution

| Evaluation Platform: Synaptics Dolphin NPU |
| Powered by: |  |
Video Super-Resolution

| Evaluation Platform: Snapdragon Adreno GPU |
| Powered by: | |
Depth Estimation

| Evaluation Platform: Raspberry Pi 4 |
| Powered by: |  |
Camera Scene Detection

| Evaluation Platform: Apple Bionic |
| Powered by: |  |
HDR Image Processing

| Evaluation Platform: Kirin Da Vinci NPU |
| Powered by: |  |
NTIRE 2021 Workshop

| Find more Classical Image Restoration Challenges |
| Powered by: | |
CALL FOR PAPERS
Being a part of CVPR 2021, we invite the authors to submit high-quality original papers proposing various machine learning based solutions for mobile, embedded and IoT platforms. The topics of interest cover all major aspects of AI and deep learning research for mobile devices including, but not limited to:
• Efficient deep learning models for mobile devices |
• Image / video super-resolution on low-power hardware |
• General smartphone photo and video enhancement |
• Deep learning applications for mobile camera ISPs |
• Fast image classification / object detection algorithms |
• Real-time semantic image segmentation |
• Image or sensor based identity recognition |
• Activity recognition using smartphone sensors |
• Depth estimation w/o multiple cameras |
• Portrait segmentation / bokeh effect rendering |
• Perceptual image manipulation on mobile devices |
• NLP models optimized for mobile inference |
• Artifacts removal from mobile photos / videos |
• RAW image and video processing |
• Low-power machine learning inference |
• Machine and deep learning frameworks for mobile devices |
• AI performance evaluation of mobile and IoT hardware |
• Industry-driven applications related to the above problems |
To ensure high quality of the accepted papers, all submissions will be evaluated by research and industry experts from the corresponding fields. All accepted workshop papers will be published in the CVPR 2021 Workshop Proceedings by Computer Vision Foundation Open Access and IEEE Xplore Digital Library. The authors of the best selected papers will be invited to present their work during the actual workshop event at CVPR 2021. The detailed submission instructions and guidelines can be found here.
TIMELINE
| Challenge Event | Date [ 5pm Pacific Time, 2021 ] |
|---|---|
| Website online | January 7 |
| Train / validation data released | January 15 |
| Validation server online | January 20 |
| Final test data released | March 15 |
| Final models / recontruction results submission deadline | March 20 |
| Fact sheets / codes submission deadline | March 20 |
| Preliminary test results released to the participants | March 22 |
| Paper submission deadline / challenge papers only ! | April 4 |
| Workshop Event | Date [ 5pm Pacific Time, 2021 ] |
|---|---|
| Paper submission server online | January 15 |
| Paper submission deadline | March 15 |
| Paper decision notification | April 5 |
| Camera ready deadline | April 15 |
| Workshop day | June 20 |
SUBMISSION DETAILS
| Format and paper length | A paper submission has to be in English, in pdf format, and at most 8 pages (excluding references) in double column. The paper format must follow the same guidelines as for all CVPR 2021 submissions: http://cvpr2021.thecvf.com/node/33 |
| Author kit | The author kit provides a LaTeX2e template for paper submissions. Please refer to this kit for detailed formatting instructions: http://cvpr2021.thecvf.com/sites/default/files/2020-09/cvpr2021AuthorKit_2.zip |
| Double-blind review policy | The review process is double blind. Authors do not know the names of the chair / reviewers of their papers. Reviewers do not know the names of the authors. |
| Dual submission policy | Dual submission is allowed with CVPR2021 main conference only. If a paper is submitted also to CVPR and accepted, the paper cannot be published both at the CVPR and the workshop. |
| Proceedings | Accepted and presented papers will be published after the conference in CVPR Workshops proceedings together with the CVPR2021 main conference papers. |
| Submission site | https://cmt3.research.microsoft.com/MAI2021 |
RUNTIME VALIDATION
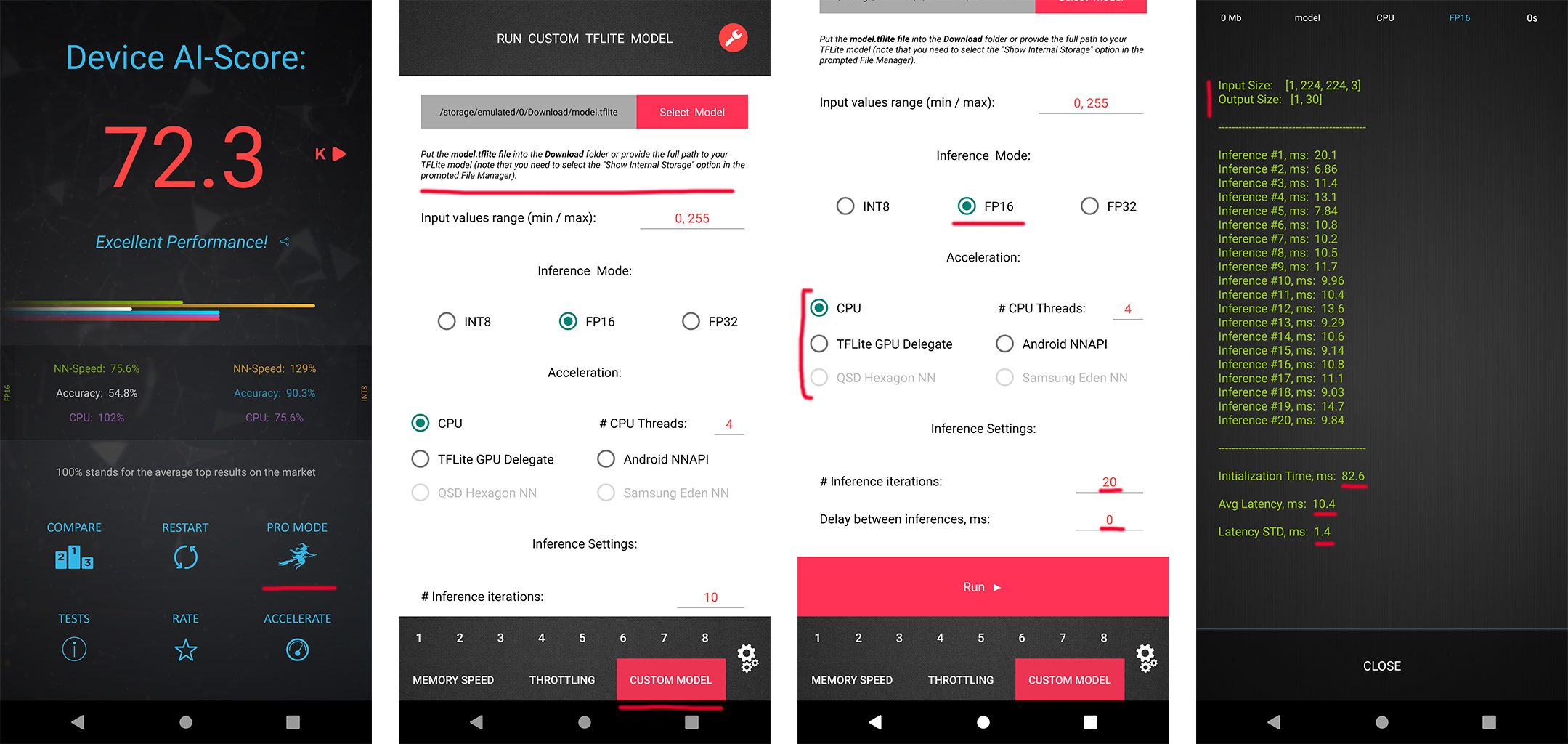
In each MAI 2021 challenge track, the participants have a possibility to check the runtime of their solutions remotely on the target platforms. For this, the converted TensorFlow Lite models should be uploaded to Codalab or special web-server, and their runtime on the actual target devices will be returned instantaneously or withing 24 hours, depending on the track. The detailed model conversion instructions and links can be found in the corresponding challenges. Besides that, we strongly encourage the participants to check the speed and RAM consumption of the obtained models locally on your own Android devices. This will allow you to perform model profiling and debugging faster and much more efficiently. To do this, one can use AI Benchmark application allowing you to load a custom TFLite model and run it with various acceleration options, including CPU, GPU, DSP and NPU: 1. Download AI Benchmark from the Google Play / website and run its standard tests. 2. After the end of the tests, enter the PRO Mode and select the Custom Model tab there. 3. Rename the exported TFLite model to model.tflite and put it into the Download folder of your device. 4. Select your mode type, the desired acceleration / inference options and run the model. You can find the screenshots demonstrating these 4 steps below:
CONTACTS
 |
Computer Vision Lab ETH Zurich, Switzerland andrey@vision.ee.ethz.ch |
 |
Computer Vision Lab ETH Zurich, Switzerland timofter@vision.ee.ethz.ch |
Computer Vision Laboratory, ETH Zurich
Switzerland, 2021