

Copyright © 2022 by A.I.
ETH Zurich, Switzerland
The benchmark consists of 46 AI and Computer Vision tests performed by neural networks running on your smartphone. It measures over 100 different aspects of AI performance, including the speed, accuracy, initialization time, etc. Considered neural networks comprise a comprehensive range of architectures allowing to assess the performance and limits of various approaches used to solve different AI tasks. A detailed description of the 14 benchmark sections is provided below.
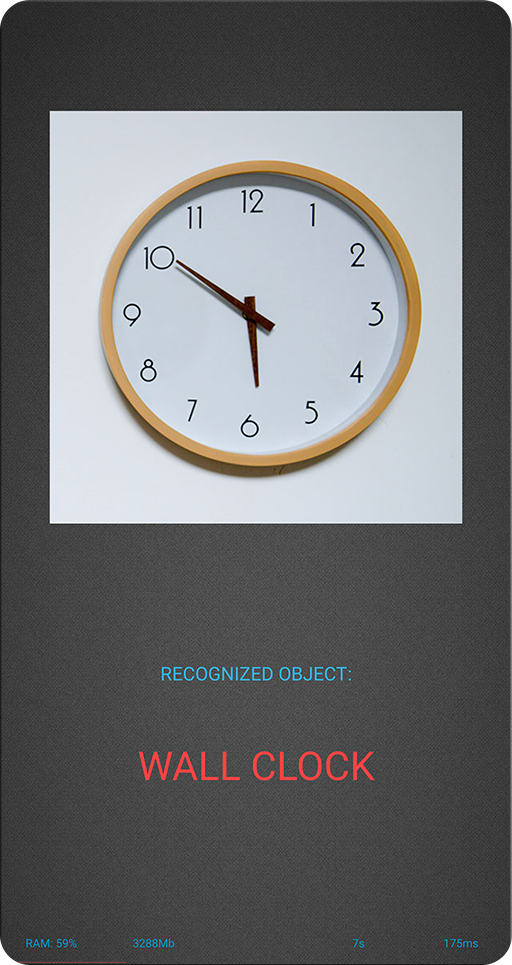
Section 1: Object Recognition / Classification
Neural Network: MobileNet - V2 | INT8 + FP16
Image Resolution: 224 x 224 px
Accuracy on ImageNet: 71.9 %
Paper & Code Links: paper / code
A very small yet already powerful neural network that is able to recognize 1000 different object classes based on a single photo with an accuracy of ~72%. After quantization, its size is less than 4Mb, which together with its low RAM consumption allows to lanch it on almost any currently existing smartphone.

Section 2: Object Recognition / Classification
Neural Network: Inception - V3 | INT8 + FP16
Image Resolution: 346 x 346 px
Accuracy on ImageNet: 78.0 %
Paper & Code Links: paper / code
A different approach for the same task: now significantly more accurate, but at the expense of 6x larger size and tough computational requirements. As a clear bonus — can process images of higher resolutions, which allows more accurate recognition and smaller object detection.

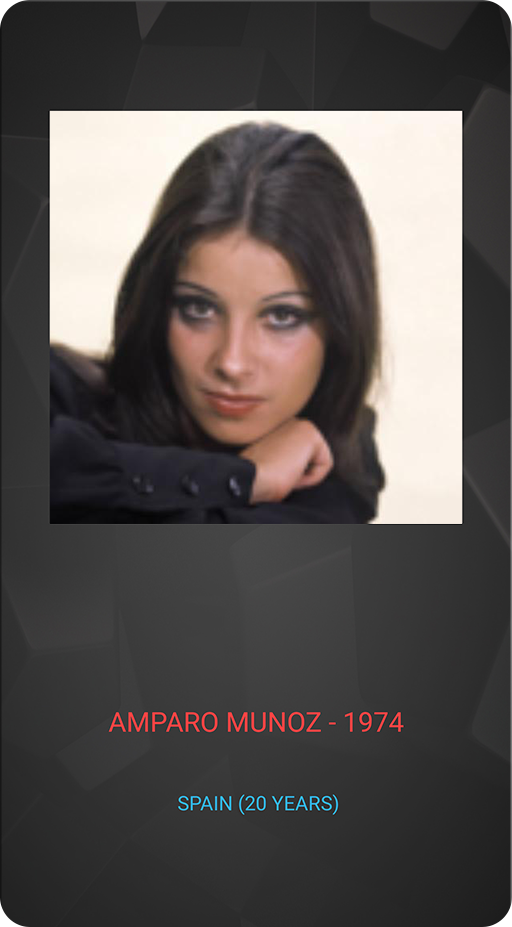
Section 3: Face Recognition
Neural Network: MobileNet - V3 Large-M | INT8 + FP16
Image Resolution: 512 x 512 px
Accuracy on ImageNet: 72.2 %
Paper & Code Links: paper / code
This task probably doesn't need an introduction: based on the face photo you want to identify the person. This is done in the following way: for each face image, a neural network produces a small feature vector that encodes the face and is invariant to its scaling, shifts and rotations. Then this vector is used to retrieve the most similar vector (and the respective identity) from your database that contains the same information about hundreds or millions of people.

Section 4: Object Recognition / Classification
Neural Network: MobileNet - V2 | INT8 + FP16
Image Resolution: 224 x 224 px
Number of Models: 1, 2, 4 and 8
Paper & Code Links: paper / code
What happens when several programs try to run their AI models at the same time on your device? Will it be able to accelerate all of them? To answer this question, we are running up to 8 floating-point and quantized neural networks in parallel on your phone's NPU and DSP, measuring the resulting inference time for each AI model.

Section 5: Optical Character Recognition
Neural Network: CRNN / Bi-LSTM | FP16 + FP32
Image Resolution: 64 x 200 px
IC13 Score: 86.7 %
Paper & Code Links: paper / code
A very standard task performed by a very standard end-to-end trained LSTM-based CRNN model. This neural network consists of two parts: the first one is a well-knows ResNet-18 network that is used here to generate deep features for the input data, while the second one, Bidirectional Dynamic RNN, is taking these features as an input and predicts the actual words / letters on the image.
 Blurred
Blurred
 Restored
Restored
Section 6: Image Deblurring
Neural Network: PyNET - Mini | INT8 + FP16
Image Resolution: 96 x 96 px
ZRR Score: 21.19 dB
Paper & Code Links: paper / code
Remember taking blurry photos using your phone camera? So, this is the task: make them sharp again. In the simplest case, this kind of distortions is modeled by applying a Gaussian blur to uncorrupted images, and then trying to restore them back with a neural network. In this task, blur is removed by a recently presented PyNET model that is processing each input image in parallel at three different scales and is utilizing all available NPU / DSP computational resources.
 Original
Original
 Restored
Restored
Section 7: Image Super-Resolution
Neural Network: VGG - 19 | INT8 + FP16
Image Resolution: 256 x 256 px
Set-5 Score (x3): 33.66 dB
Paper & Code Links: paper / code
Have you ever zoomed you photos? Remember artifacts, lack of details and sharpness? Then you know this task from your own experience: make zoomed photos look as good as the original images. In this case, the network is trained to do an equivalent task: to restore the original photo given its downscaled (e.g., by factor of 4) version. Here we consider a deep VGG-19 model with 19 layers. While its performance isn't that amazing as it is unable to recover high-frequency components, it is still an ideal solution for paintings and drawings: it makes them sharp but smooth.
 Original
Original
 Restored
Restored
Section 8: Image Super-Resolution
Neural Network: SRGAN | INT8 + FP16
Image Resolution: 512 x 512 px
Set-5 Score (x3): 29.40 dB
Paper & Code Links: paper / code
The same task, but with new tricks: what if we train our neural network using... another neural network? Yes, two network performing two tasks: network A is trying to solve the same super-resolution problem as above, while network B observes its results, tries to find there some drawbacks and then penalizes network A. Sounds cool? In fact, it is cool: while this approach used by the SRGAN model has its own issues, the produced results are often looking really amazing.
 Original
Original
 Bokeh
Bokeh
Section 9: Bokeh Simulation
Neural Network: U-Net | INT8 + FP16
Image Resolution: 384 x 384 px
ISBI (IoU): 0.9203
Paper & Code Links: paper / code
Probably one of the most well-known and popular AI task on smartphones — blurring the background like on high-end DSLRs: just select the Portrait Mode in the camera app to see how it works on your Android or iOS device. In this section, a relatively large U-Net convolutional neural network capable of doing heavy image processing is used to render bokeh effect without the need of multiple cameras: after being pre-trained, it can add an artistic blur to arbitrary images. Not always flawlessly, but still quite impressive.
 Original
Original
 Segmented
Segmented
Sections 10-11: Semantic Segmentation
Neural Network: DeepLab-V3+ | INT8 + FP16
Image Resolution: 513 x 513 px
CityScapes (mIoU): 82.1 %
Paper & Code Links: paper / code
Running Self-Driving algorithm on your phone? Yes, that's possible too, at least you can perform a substantial part of this task — detect 19 categories of objects (e.g. car, pedestrian, road, sky, etc.) based on the photo from the camera mounted inside the car. On the right image, one can see the results of such pixel-size semantic segmentation (each color correpsonds to each object class) for a very popular DeepLab-V3+ network designed specifically for low-power devices.
 Original
Original
 Enhanced
Enhanced
Section 12: Photo Enhancement
Neural Network: DPED-ResNet | INT8 + FP16
Image Resolution: 128 x 192 px
DPED PSNR i-Score: 18.11 dB
Paper & Code Links: paper / paper / code
Struggling when looking at photos from your old phone? This can be fixed: a properly trained neural network can make photos even from an ancient iPhone 3GS device looking nice and up-to-date. To achieve this, it observes and learns how to transform photos from a low-quality device into the same photos from a high-end DSLR camera. Of course, there are some obvious limitations for this magic (e.g., the network should be retrained for each new phone model), but the resulting images are looking quite good, especially for old devices.

Section 13: Text Completion
Neural Network: Static RNN / LSTM | FP16
Embeddings Size: 32 x 500
Layers | LSTM Units: 4 | 512
Paper & Code Links: paper / code
Yet another standard deep learning problem on smartphones — providing text suggestions based on what the user types. In this task, we consider a variation of this NLP task: a simple static LSTM model learns to fill in the gaps in the text using sentence semantics inferred from the provided Word2vec word embeddings.
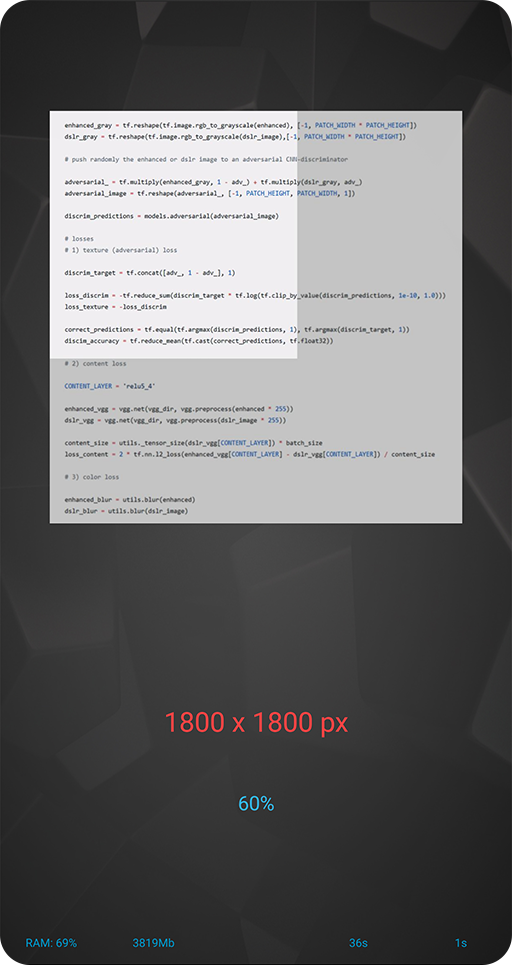
Section 14: Memory Limits
Neural Network: SRCNN 9-5-5 | FP16
Image Resolution: 4 MP
# Parameters: 69.162
Paper & Code Links: paper / code
SRCNN is one of the oldest, simplest and lightest neural networks that consists of only 3 convolutional layers. However, even it can bring the majority of phones to their knees while handling high-resolution photos: to process HD-images the phone should generally have at least 4GB of RAM. This test is aimed at finding the limits of your device: how big images can it handle with this simplest network?
Copyright © 2022 by A.I.
ETH Zurich, Switzerland